My prediction for the next two years: Apple, Symantec, McAffee, Oracle etc. will get pounded into the ground by lots of bugs being found and disclosed through security researchers that are looking for easier targets than the current MS codebase. And the abovementioned companies won't have monopoly revenue to throw around and fix the issues.
This is a big opportunity for MS to move into all their markets :-) and sell their products as superior on the security side.
While I am in "evil" mood: The german train system is about to be IPO'ed, and there's a lot of debate going on here about details of the contract. What is most interesting but not being debated:
All real estate owned by the Deutsche Bahn AG (the privatized version of the german train system that is going to be floated) is in the books with it's value upon acquisition -- meaning it's value in 1935. The real estate in possession of the DB is, by today's value, worth several times more than the total money they expect to get out of the IPO.
If I was an investment banker, I'd gang up with a bunch of private equity folks, buy the majority in the DB AG once it is IPO'd, and then sell of the real estate. Other countries (USA, Britain) survive without a decent train system, too, and I wouldn't care as I'd have a Rolls and a driver.
Allright, enough of the devil's advocate mode. It was fun seeing my brother the last weekend,
and we always come up with good ideas ;)
Tuesday, May 23, 2006
Saturday, May 20, 2006
 The Vodafone virus dropped by today and brought us some mobile viruses to play with - thanks ! :-)
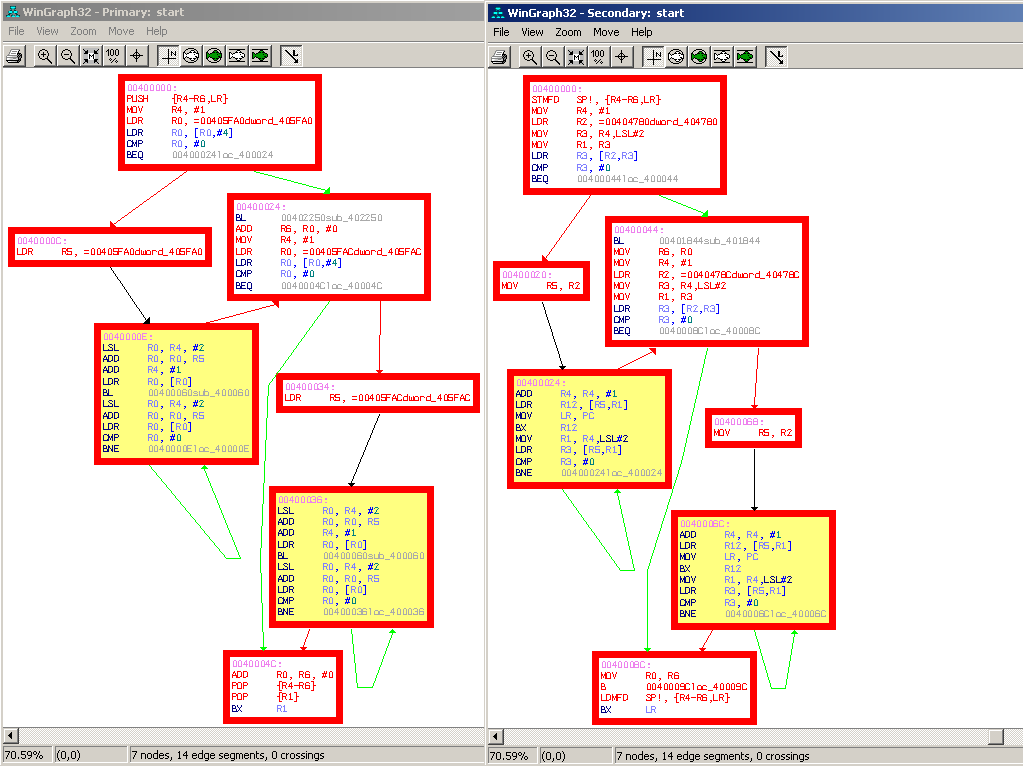
The Vodafone virus dropped by today and brought us some mobile viruses to play with - thanks ! :-)So cross-platform diffing can be fun -- Rolf ran a diff of Commwarrior.B against Commwarrior.C today, and while B is compiled for standard ARM, C is compiled in 'thumb mode', which is pretty much the same as being compiled for a different CPU (thumb means that all instructions are different).
The amusing result is that even though the compilation is for a different platform, we still get roughly 61% of the functions matched. And the functions, which are clearly the same on the 'structural' (e.g. flowgraph) - level, have completely different instructions, and manual inspection will confirm that these differing instructions end up doing the same.
For those of you that want to verify things manually, click here.
Quote from Lock, Stock and Two Smoking Barrels: "I don't care who you use as long as they are not complete muppets".
Having MSOffice 0day is not terribly hard, but one should not burn it by making it drop standard, off-the-shelf, poorly-written bot software. The stealth advantage that one has by sending .DOC files into an organisation should not be given up by creating empty SYS files or dropping DLLs.
Also, registry key adding for getting control on reboot is kinda suboptimal.
I am kinda curious to know how they got caught, but my guess is that the bad QA on the internet explorer injection raised enough crashes to make people investigate.
On a side note, this highlights a few common problems people face when doing client side attacks:
Having MSOffice 0day is not terribly hard, but one should not burn it by making it drop standard, off-the-shelf, poorly-written bot software. The stealth advantage that one has by sending .DOC files into an organisation should not be given up by creating empty SYS files or dropping DLLs.
Also, registry key adding for getting control on reboot is kinda suboptimal.
I am kinda curious to know how they got caught, but my guess is that the bad QA on the internet explorer injection raised enough crashes to make people investigate.
On a side note, this highlights a few common problems people face when doing client side attacks:
- One-shot-ness -- any exploit you write is a one-shot and should work reliably
- Process recovery -- any exploit you write needs to be able to recover and have the exploited application resume as if nothing happened. This is a tad hard if you've written 200 megs of garbage to the heap.
- Lack of complete pre-attack intel on the target environment -- I don't know what went wrong when they injected into iexplore, but they must've been confident that their code was good enough. This means they tested it on a testbed which didn't reflect the actual target.
- Lack of attack focus -- I am quite convinced that they could've had a simpler, stealthier, and more stable bot component if they had thought more thoroughly about what their goal in this attack was
Friday, May 19, 2006
For those that are into malware classification, here's some code that one
can include in a piece of malware to skew the Levenshtein distance described
in the recently published MS paper.
can include in a piece of malware to skew the Levenshtein distance described
in the recently published MS paper.
int j, i = random_integer_in_range(0, 50000);
FILE *f;
for( j = 0; j < i; j++ ){
f = fopen("c:\\test.txt", "rt");
flose(f);
}
Tuesday, May 16, 2006
Behavioural classification of malware
Today is a good day: I got my math homework done before it has to be handed in, and that leaves me some free time to blog :-)
Dana Epp has a post referring to an entry by Tony Lee referencing an EICAR paper on automated malware classification using behavioural analysis. I am not totally unbiased on this as we at SABRE have been working a lot on structural classification of malware recently, so take my following criticism with a grain of salt.
I personally think the approach in the paper is suboptimal for the following reasons:
I'm not saying the paper isn't good or doesn't touch valid points, but behaviour is so trivially randomized even from a high-level-language level that the approach in the paper is next to pointless once malware authors target it.
On to something kinda different:
A more general question we have to ask ourselves is: Do we really want to measure the accuracy of new, automated malware classification algorithms by comparing them to the results of the manual classification done by AV-vendors so far, which had neither efficient information sharing nor any clear methodology as to how to name malware ? Using any sort of machine learning based on the AV-industry provided datasets needs to be very resilient to partially incorrect input data, as a good number of bots seem to be more or less arbitrarily named.
Anyhow, time to go to sleep and read Courtois eprint paper
Today is a good day: I got my math homework done before it has to be handed in, and that leaves me some free time to blog :-)
Dana Epp has a post referring to an entry by Tony Lee referencing an EICAR paper on automated malware classification using behavioural analysis. I am not totally unbiased on this as we at SABRE have been working a lot on structural classification of malware recently, so take my following criticism with a grain of salt.
I personally think the approach in the paper is suboptimal for the following reasons:
- By using behavioural data, we can only classify an executable based on things it does in the observed timeframe. Any time-delayed trigger (that e.g. triggers two months from now) is hard to see, and the application might just sleep until then. How do we classify something that just came into our networks ? We can't classify it until it starts becoming "active".
- It is trivial even for somebody who knows only rudimentary programming to modify a program so that the modifed program only has a few (~4 ?) lines of code more than the original program, yet it's Levenshtein distance as measure in the paper is arbitrarily large. As it stands, adding file writes in a loop should be enough, and the Levenshtein distance can be arbitrarily increased by more loop iterations.
- The paper cites on-access deobfuscation as a principal problem that static analysis cannot easily deal with -- but from (2) it follows that on-access deobfuscation can be coupled with Levenstein-distance-maximizing code in a trivial manner, breaking the approach that was proposed as superior in the paper. The claim that runtime analysis can effectively bypass the need to deal with obfuscation is simply not true if the application ever targets the event collection by 'junking' it with bogus events.
I'm not saying the paper isn't good or doesn't touch valid points, but behaviour is so trivially randomized even from a high-level-language level that the approach in the paper is next to pointless once malware authors target it.
On to something kinda different:
A more general question we have to ask ourselves is: Do we really want to measure the accuracy of new, automated malware classification algorithms by comparing them to the results of the manual classification done by AV-vendors so far, which had neither efficient information sharing nor any clear methodology as to how to name malware ? Using any sort of machine learning based on the AV-industry provided datasets needs to be very resilient to partially incorrect input data, as a good number of bots seem to be more or less arbitrarily named.
Anyhow, time to go to sleep and read Courtois eprint paper
Friday, May 12, 2006
Microsofts built-in firewall has some really annoying things to it. I am running a laptop connected to an untrusted network and an instance of VMWare connected on a different interface. If I disable the firewall on the VMWare interface, it automatically gets disabled on the global interface. Very cute. Can we get this fixed ?