SP's blog has a good post today:
:-)
Wednesday, December 13, 2006
Thursday, November 23, 2006
Over at the Matasano Blog :)
Matasano 's Blog quoted my post on Office bugs, and Ivan Arce made some excellent points in the comments:
Matasano 's Blog quoted my post on Office bugs, and Ivan Arce made some excellent points in the comments:
1. 'They are inherently one-shot. You send a bad file, and while the user might try to open it multiple times, there is no way the attacker can try different values for anything in order to get control.”'
IA: OK. good point but…think about scale & diversity. Even in a targeted attack sending a one-shot client-side exploit against N desktop systems will with one hardcoded address will offset the value of ALSR with some probability of success for a given N. The attacker only needs ONE exploit instance to work in order to break into ONE desktop system, after that it is game over. Client-side bugs are one shot against the same system but not necesarrilly so against several systems in parallel.
Very true, I did overlook this. It also explains the use of really low-value phone-home bots as payload: If you're going to attack in such a "wide" manner, you essentially accept detection as long as you can compromise one of the relevant clients. This means that whatever you are sending will be lost, and therefore you won't send anything more sophisticated than a simple bot.
” 2. There can not be much pre-attack reconnaissance. Fingerprinting server versions is usually not terribly difficult (if time consuming), and usually one can narrow down the exact version (and most of the times the patch level) of a target before actually shooting valuable 0day down the wire. With client side bugs, it is a lot more difficult to know the exact version of a piece of software running on the other side - one probably has to get access to at least one document created by the target to get any data at all, and even this will usually be a rough guesstimate.”
IA: Hmmm not sure about this either. I would argue the desktop systems (clients) leak A LOT more information about themselves than servers and, generally, those leaks are much less controlled and/or controllable and easier to elicit than server leaks. After all, as a general principle, client apps are _designed_ to provide information about themselves.
Not to mention that a lot of information about your desktop systems has *already* leaked and is publicly available on the net now (server logs, emails, documents, stray packets, etc.), you just need to know how and where to look for it.
I disagree on this to an extent. My system leaks information about my mail client because I participate in public forums etc, but the majority of corporate users never gain any visibility outside of the internal network. Most people just don't use mailing lists or usenet etc. So it will be comparatively easy to attack some security officer (hey, I know his exact client version), but the CEO's secretary (which might be a lot more interesting as a target, and less likely to notice her computer is compromised) will be more or less "invisible".
Tuesday, November 21, 2006
Unbelievable but true
I am decompressing a bit after a few weeks of insane stress and thus I am actually reading blogs. And to my greatest surprise, I ended up reading this one. Now, Oracle security has never interested me ever since I tried to audit it in 2000 and it kept falling over without a fight (or without us really doing anything except sending a few letters to it), but I have to admit that Ms. Davidsons blog has a pretty high entertainment value (at least for me, a morallically degenerate piece of eurotrash full of the afterglow of a once good education system), AND it is refreshing to see someone with a bit of a classical education in IT security (I get picked upon regularly for the fact that I got my Latinum "on the cheap" and know jack shit about old greek - then again, my circle of friends includes a mathematician that claims that he can, by means of listening to a record, tell you in which church in france a certain piece of organ music was played, and hence I am always the loud and stupid one).
Anyhow, given Oracle's horrible code quality, I am very much positively surprised at the quality of Ms. Davidsons blog. And given what most people that have worked with static analysis tools before would describe as a horrible mistake in evaluating tool quality, I would like to mention that mathematics and geometry are part of a classical education. Whoever decided on the right source code analysis tool to use for detecting flaws in Oracle apparently failed that part.
I am decompressing a bit after a few weeks of insane stress and thus I am actually reading blogs. And to my greatest surprise, I ended up reading this one. Now, Oracle security has never interested me ever since I tried to audit it in 2000 and it kept falling over without a fight (or without us really doing anything except sending a few letters to it), but I have to admit that Ms. Davidsons blog has a pretty high entertainment value (at least for me, a morallically degenerate piece of eurotrash full of the afterglow of a once good education system), AND it is refreshing to see someone with a bit of a classical education in IT security (I get picked upon regularly for the fact that I got my Latinum "on the cheap" and know jack shit about old greek - then again, my circle of friends includes a mathematician that claims that he can, by means of listening to a record, tell you in which church in france a certain piece of organ music was played, and hence I am always the loud and stupid one).
Anyhow, given Oracle's horrible code quality, I am very much positively surprised at the quality of Ms. Davidsons blog. And given what most people that have worked with static analysis tools before would describe as a horrible mistake in evaluating tool quality, I would like to mention that mathematics and geometry are part of a classical education. Whoever decided on the right source code analysis tool to use for detecting flaws in Oracle apparently failed that part.
Client Side Exploits, a lot of Office bugs and Vista
I have ranted before about careless use of 0day by seemingly chinese attackers, and I think I have finally understood why someone would use good and nice bugs in such a careless manner:
The bugs are going to expire soon. Or to continue using Dave Aitel's and my terminology: The fish are starting to smell.
ASLR is entering the mainstream with Vista, and while it won't stop any moderately-skilled-but-determined attacker from compromising a server, it will make client side exploits of MSOffice file format parsing bugs a lot harder.
Client-side bugs suffer from a range of difficulties:
So you're in a situation where you're sitting on heaps of 0day in MSOffice, which, contrary to Vista, was not the biggest (private sector) pentest ever (This sentence contains two inside jokes, and I hope that those who understand them aren't mad at me :-). What do you do with those that are going to be useless under ASLR ? Well, damn, just fire them somewhere, with some really silly phone-home-bots inside. If they bring back information, fine, if not, you have not actually lost much. The phone-home bots are cheap to develop (in contrast to a decent rootkit) and look amateurish enough as to not provoke your ambassador being yelled at.
If you are really lucky, you might actually get your opponent to devote time and resources to countermeasures against MS Office bugs, in the hope they don't realize that work will be taken care of elsewhere. In the meantime, you hone your skills in defeating ASLR through out-of-defined-memory-read-bugs (see some blog post in the next few days).
On a side note, I am terribly happy today. I've had more luck this week than I deserve.
I have ranted before about careless use of 0day by seemingly chinese attackers, and I think I have finally understood why someone would use good and nice bugs in such a careless manner:
The bugs are going to expire soon. Or to continue using Dave Aitel's and my terminology: The fish are starting to smell.
ASLR is entering the mainstream with Vista, and while it won't stop any moderately-skilled-but-determined attacker from compromising a server, it will make client side exploits of MSOffice file format parsing bugs a lot harder.
Client-side bugs suffer from a range of difficulties:
- They are inherently one-shot. You send a bad file, and while the user might try to open it multiple times, there is no way the attacker can try different values for anything in order to get control.
- There can not be much pre-attack reconnaissance. Fingerprinting server versions is usually not terribly difficult (if time consuming), and usually one can narrow down the exact version (and most of the times the patch level) of a target before actually shooting valuable 0day down the wire. With client side bugs, it is a lot more difficult to know the exact version of a piece of software running on the other side - one probably has to get access to at least one document created by the target to get any data at all, and even this will usually be a rough guesstimate.
So you're in a situation where you're sitting on heaps of 0day in MSOffice, which, contrary to Vista, was not the biggest (private sector) pentest ever (This sentence contains two inside jokes, and I hope that those who understand them aren't mad at me :-). What do you do with those that are going to be useless under ASLR ? Well, damn, just fire them somewhere, with some really silly phone-home-bots inside. If they bring back information, fine, if not, you have not actually lost much. The phone-home bots are cheap to develop (in contrast to a decent rootkit) and look amateurish enough as to not provoke your ambassador being yelled at.
If you are really lucky, you might actually get your opponent to devote time and resources to countermeasures against MS Office bugs, in the hope they don't realize that work will be taken care of elsewhere. In the meantime, you hone your skills in defeating ASLR through out-of-defined-memory-read-bugs (see some blog post in the next few days).
On a side note, I am terribly happy today. I've had more luck this week than I deserve.
Monday, November 20, 2006
While we're all talking about the next overflow and think that they have significance in the wider scheme of things, I'll climb on the soapbox for 5 minutes:
We should send peacekeeping troops to Darfour/Sudan. I was strongly opposed to the Iraq war (on the ground that invasion would bring civil war), but I plead my government: Take my taxes and send peacekeeping forces to Sudan. _If_ we have decided that the 'europeans-are-from-venus'-stance is obsolete, we have here a primary example of a conflict where external invasion appears necessary according to almost everybody (except the government in Kartoum).
We should send peacekeeping troops to Darfour/Sudan. I was strongly opposed to the Iraq war (on the ground that invasion would bring civil war), but I plead my government: Take my taxes and send peacekeeping forces to Sudan. _If_ we have decided that the 'europeans-are-from-venus'-stance is obsolete, we have here a primary example of a conflict where external invasion appears necessary according to almost everybody (except the government in Kartoum).
Thursday, October 05, 2006
While I am blogging about strange hobbies: I used to draw a lot, and still appreciate a few comics. Most importantly, local cult hero Jamiri.
Some examples:
http://www.spiegel.de/netzwelt/netzkultur/0,1518,grossbild-650193-422928,00.html
http://www.spiegel.de/netzwelt/netzkultur/0,1518,grossbild-669475-427889,00.html
Some examples:
http://www.spiegel.de/netzwelt/netzkultur/0,1518,grossbild-650193-422928,00.html
http://www.spiegel.de/netzwelt/netzkultur/0,1518,grossbild-669475-427889,00.html
I am known for odd hobbies and interests, and for a long while, I have been very fascinated with all forms of syncretism, specifically carribbean syncretism.
For various private reasons I am exposed to quite a bit of information about social anthropology, and I usually find the descriptions of odd rites in various societies very amusing and enlightening.
For example, any diagram of multi-family cross-cousin-marriage in some african societies just brings out the graph theory nerd in me, and serious scientific texts debating the difference between endo- and exocannibalism (eat your own tribe vs. eat the other tribe) are a fun diversion from reading dry stuff all day.
Yet I was unprepared for reading about the "Cargo Cult" today. And thinking about it, the sheer fact that a cargo cult developed in Melanesia makes me want to laugh and cry at the same time.
Read it. It's worth it.
For various private reasons I am exposed to quite a bit of information about social anthropology, and I usually find the descriptions of odd rites in various societies very amusing and enlightening.
For example, any diagram of multi-family cross-cousin-marriage in some african societies just brings out the graph theory nerd in me, and serious scientific texts debating the difference between endo- and exocannibalism (eat your own tribe vs. eat the other tribe) are a fun diversion from reading dry stuff all day.
Yet I was unprepared for reading about the "Cargo Cult" today. And thinking about it, the sheer fact that a cargo cult developed in Melanesia makes me want to laugh and cry at the same time.
Read it. It's worth it.
Friday, September 08, 2006
After all the Brouhaha surrounding the work on Apple wireless drivers, I'd like to pitch my two cents:
I am not decided on the paper yet - read it yesterday evening, jetlagged, over half a bottle of wine. This sort of publishing would be very easy for hash functions -- I would believe anyone that he can build secondary pre-images (or even pre-images) from MD5 if he can give me a string of input that hashes to "thequickbrownfox....".
Now, we just need stuff like that for bugs ;-)
- Who cares wether this is real or not ? The possibility of breaking NIC drivers (especially in multithreaded kernels) is real, and nobody should be surprised if this happens. Has anyone ever disassembled the pos drivers that come with every cheap electronic USB gadget ? I have my doubts that the QA for NIC drivers is a lot better
- It seems we are not the only ones with a similar problem: http://eprint.iacr.org/2006/303.ps
I am not decided on the paper yet - read it yesterday evening, jetlagged, over half a bottle of wine. This sort of publishing would be very easy for hash functions -- I would believe anyone that he can build secondary pre-images (or even pre-images) from MD5 if he can give me a string of input that hashes to "thequickbrownfox....".
Now, we just need stuff like that for bugs ;-)
Monday, August 21, 2006
Now with all this noise surrounding the ConsumerReports article where they created 5500 new virus variants, I would really like to get my hands on their sample list to see how VxClass, our malware classification engine, deals with them.
Friday, August 11, 2006
From Matasano:
"The results of one trace can be used to filter subsequent traces. This is huge (in fairness: it’s something that other people, notably Halvar [I believe], have been working on)."
I have to admit that our flash movies that we posted last year in September are mind-numbingly boring, but they do show this sort of stuff ;) -- BinNavi was able to record commentable debug traces since day 1.
http://www.sabre-security.com/products/BinNavi/flash_binnavi_debugger.html
http://www.sabre-security.com/products/BinNavi/flash.html
The entire idea of breakpointing on everything and doing differential debugging dates back to at least a Blackhat presentation in Vegas 2002. Fun stuff, and good to see that with PaiMei there is finally a free framework to do this.
I really need to re-do the BinNavi movies in the next weeks, they really do not do our product any justice any more.
To continue shamelessly plugging my product :-):
"Can I have stack traces for each hit? I know they’re somewhat redundant, but I can graph them to visualize control flow (in particular, to identify event and “parse” loops)."
You can in the next release (scheduled for October) where you can attach arbitrary python scripts to breakpoints and thus do anything to memory you want.
"Yeah, I need this for non-Windows targets. Remote debugging is apparently coming, which will help. I don’t imagine Pedram’s working on SPARC support (X86 and Win32 has eaten its way pretty thoroughly through the code). Also,"
We have Linux/ptrace support and a (very experimental) WinCE/ARM support.
I promise to redo the movies in the next weeks.
Enough of the advertisement crap.
Cheers,
Halvar
"The results of one trace can be used to filter subsequent traces. This is huge (in fairness: it’s something that other people, notably Halvar [I believe], have been working on)."
I have to admit that our flash movies that we posted last year in September are mind-numbingly boring, but they do show this sort of stuff ;) -- BinNavi was able to record commentable debug traces since day 1.
http://www.sabre-security.com/products/BinNavi/flash_binnavi_debugger.html
http://www.sabre-security.com/products/BinNavi/flash.html
The entire idea of breakpointing on everything and doing differential debugging dates back to at least a Blackhat presentation in Vegas 2002. Fun stuff, and good to see that with PaiMei there is finally a free framework to do this.
I really need to re-do the BinNavi movies in the next weeks, they really do not do our product any justice any more.
To continue shamelessly plugging my product :-):
"Can I have stack traces for each hit? I know they’re somewhat redundant, but I can graph them to visualize control flow (in particular, to identify event and “parse” loops)."
You can in the next release (scheduled for October) where you can attach arbitrary python scripts to breakpoints and thus do anything to memory you want.
"Symbols. Pedram acknowledges this in his presentation. It didn’t slow me down much not to have them, but it feels weird."
If IDA has them, BinNavi has them.
"I need to be able to click on a hit and see the assembly for it (if there’s a way to click on something and have it pop up in IDA, so much the better)."
Right-click->open subfunction in BinNavi ;)"Yeah, I need this for non-Windows targets. Remote debugging is apparently coming, which will help. I don’t imagine Pedram’s working on SPARC support (X86 and Win32 has eaten its way pretty thoroughly through the code). Also,"
We have Linux/ptrace support and a (very experimental) WinCE/ARM support.
I promise to redo the movies in the next weeks.
Enough of the advertisement crap.
Cheers,
Halvar
Wednesday, July 26, 2006
The security world never ceases to amaze me. A few years ago, a few friends of mine would run around security conferences and drunkenly yell "fuzz tester ! fuzz tester !" at people that, well, fuzzed. I found this really hilarious.
What I find amazing though is that fuzzers are now being seriously discussed in whitepapers and even called "artificial intelligence". Folks, can we please NOT do the time warp again ? And can we please start writing about something new ?
On a side note: Since I am a bit of a language nerd, I can't fail to notice that "artificial intelligence" takes a semantically cool twist when mentioned in the same sentence as "yellowcake from africa".
PS: This post is a rant about people that write about fuzzing as a new threat, not about people that write and use fuzzers. Just to clarify :)
What I find amazing though is that fuzzers are now being seriously discussed in whitepapers and even called "artificial intelligence". Folks, can we please NOT do the time warp again ? And can we please start writing about something new ?
On a side note: Since I am a bit of a language nerd, I can't fail to notice that "artificial intelligence" takes a semantically cool twist when mentioned in the same sentence as "yellowcake from africa".
PS: This post is a rant about people that write about fuzzing as a new threat, not about people that write and use fuzzers. Just to clarify :)
Tuesday, July 11, 2006
The article at this link is a bit funny, but if it is true that Materazzi made racial slurs against Zidane, then his headbutt was the ONLY proper answer to that.
Racism on the pitch should not be tolerated under any circumstances, and a healthy team would not tolerate racist remarks from any team member.
If Zidane's reaction was a response to racist remarks, then his headbutt is a symbol for a world cup that did not tolerate racism, and that united people from all over the world instead of dividing them.
On a side note, I am very happy for all the Italians :-) and I'd like to thank my Italian neighbours for having invited us to their place to watch the final.
Enough football, now back to work.
Racism on the pitch should not be tolerated under any circumstances, and a healthy team would not tolerate racist remarks from any team member.
If Zidane's reaction was a response to racist remarks, then his headbutt is a symbol for a world cup that did not tolerate racism, and that united people from all over the world instead of dividing them.
On a side note, I am very happy for all the Italians :-) and I'd like to thank my Italian neighbours for having invited us to their place to watch the final.
Enough football, now back to work.
Monday, July 10, 2006
I know that I am going to draw the hate of many people for this post, but I refuse to think less of Zidane for the headbutt against Materazzi. As strange as it sounds, for some reason I am quite convinced that he must have had a good reason for this.
Nobody is mad enough to just headbutt an opponent in the worldcup finals in the last game of a legendary career unless he has a very good reason.
But well.
Nobody is mad enough to just headbutt an opponent in the worldcup finals in the last game of a legendary career unless he has a very good reason.
But well.
Tuesday, July 04, 2006
Sunday, July 02, 2006
This Ebay posting for a Yacht that was previously owned by China's Minister of Defense might in fact be a bargain -- I would assume one automatically buys not only the yacht but also some state-of-the-art (of the mid-90's) electronics. I am not sure if that is still worth 2m USD, but still.
Saturday, July 01, 2006
I used to read security blogs via http://www.dayioglu.net/planet/ , which now seems down.
It's amusing how quickly I have quit reading blogs since. Funny world.
It's amusing how quickly I have quit reading blogs since. Funny world.
Saturday, June 24, 2006
On bug disclosure and contact with vendors
After reading HDM's blog entry on interaction with MS on one of the recent bugs, I guess I should drop my 2c's worth of opinion into the bowl regarding bug disclosure:
So sometimes I get the urge to find bugs. Then I go out and sometimes I find bugs. Then I usually feel quite happy and sometimes I even write an exploit. I do all this out of personal enjoyment -- I like bugs. I like having to play carambolage billard to get an exploit to work (meaning having to bounce things off of each other in weird angles to get stuff to work). Now, of course, once I am done I have several options on what to do with a bug.
In case 2), I get a warm handshake, some money, and a feeling of guilt for having given my dog to a total stranger.
In case 3), I have something to look at with fond memories and have to invest no time at all into things that I don't find interesting.
What would be your choice ?
After reading HDM's blog entry on interaction with MS on one of the recent bugs, I guess I should drop my 2c's worth of opinion into the bowl regarding bug disclosure:
So sometimes I get the urge to find bugs. Then I go out and sometimes I find bugs. Then I usually feel quite happy and sometimes I even write an exploit. I do all this out of personal enjoyment -- I like bugs. I like having to play carambolage billard to get an exploit to work (meaning having to bounce things off of each other in weird angles to get stuff to work). Now, of course, once I am done I have several options on what to do with a bug.
- Report it to the vendor. This would imply the following steps, all of which take up time and effort better spent on doing something interesting:
- Send mail to their secure@ address, requesting an encryption key. I think it is amusing that some vendors like to call security researchers irresponsible when the default channel for reporting vulnerabilities is unencrypted. That is about as irresponsible as the researchers talking about vulnerabilities on EFNET.
- Get the encryption key. Spend time writing a description. Send the description, possibly with a PoC.
- MSRC is a quite skilled bunch, but with almost any other software vendor, a huge back and forth begins now where one has to spend time explaining things to the other side. This involves writing boring things explaining boring concepts etc.
- Sell it to somebody who pays for vulnerabilities. While this will imply the same lengthy process as mentioned above, at least one can in theory get paid for it. Personally, I wouldn't sell bugs, but that could have several reasons:
- I am old and lame and can't find bugs that are good enough any more
- The few bugs that I find are too close to my heart to sell -- each good bug and each good exploit has a story, and I am not so broke that I'd need to sell something that I consider inherently beautiful
- I don't know the people buying these things. I don't know what they'd do with it. I wouldn't give my dog to a total stranger either.
- Keep it. Perhabs on a shelf, or in a frame. This implies zero effort on my side. It also gives me the joy of being able to look at it on my wall and think fondly of the story that it belonged to.
In case 2), I get a warm handshake, some money, and a feeling of guilt for having given my dog to a total stranger.
In case 3), I have something to look at with fond memories and have to invest no time at all into things that I don't find interesting.
What would be your choice ?
Friday, June 23, 2006
I really enjoyed reading Ilfak's blog post today :-) -- it always makes me happy to see clever abstractions and the results they produce. And I really enjoy original ideas (of which there seems to be a very finite amount in IT :)
Monday, June 12, 2006
Compression, Statistics and such
In the process of doing the usual stuff that I do when I do not struggle with my studies, I ran into the problem of having a number of streams with a very even distribution of byte values. I know that these bytes are executable code somehow encoded. I have a lot of reason to suspect that they are compressed, not encrypted, but I have not been able to make sense of it yet.
This brought me to the natural question: Do common encryption algorithms have statistical fingerprints that would allow them to be distinguished from one another, more-or-less irrespective of the underlying data ? It is clear that this gets harder as the amount of redundancy decreases.
It was surprising (at least for me) that nobody else has worked on this yet (publically).
Also, it made me regret that due to some time constraints involving some more algebraic courses I was unable to attend the Statistics I and II lectures given at my University by Prof. Dette. Had I attended, I would know better how to make sense of the capabilities that software like R could give me.
Another example of the fundamental law of mathematics: For every n denoting the number of days you have studied mathematics there exists a practical problem that make you wish you had studied 2n days already.
In the process of doing the usual stuff that I do when I do not struggle with my studies, I ran into the problem of having a number of streams with a very even distribution of byte values. I know that these bytes are executable code somehow encoded. I have a lot of reason to suspect that they are compressed, not encrypted, but I have not been able to make sense of it yet.
This brought me to the natural question: Do common encryption algorithms have statistical fingerprints that would allow them to be distinguished from one another, more-or-less irrespective of the underlying data ? It is clear that this gets harder as the amount of redundancy decreases.
It was surprising (at least for me) that nobody else has worked on this yet (publically).
Also, it made me regret that due to some time constraints involving some more algebraic courses I was unable to attend the Statistics I and II lectures given at my University by Prof. Dette. Had I attended, I would know better how to make sense of the capabilities that software like R could give me.
Another example of the fundamental law of mathematics: For every n denoting the number of days you have studied mathematics there exists a practical problem that make you wish you had studied 2n days already.
Monday, June 05, 2006
Some shameless self-promotion: Rolf and me are going to teach a special one-day class on BinDiff 2 at BlackHat Las Vegas this year:
http://www.blackhat.com/html/bh-usa-06/train-bh-us-06-hf-sabre.html
We'll cover applications of BinDiff to malware analysis, detecting Code Theft and GPL violations, and of course the usual patch analysis.
http://www.blackhat.com/html/bh-usa-06/train-bh-us-06-hf-sabre.html
We'll cover applications of BinDiff to malware analysis, detecting Code Theft and GPL violations, and of course the usual patch analysis.
Saturday, June 03, 2006
Sunday, May 28, 2006
My prediction for the next two years: Apple, Symantec, McAffee, Oracle etc. will get pounded into the ground by lots of bugs being found and disclosed through security researchers that are looking for easier targets than the current MS codebase. And the abovementioned companies won't have monopoly revenue to throw around and fix the issues.
This is a big opportunity for MS to move into all their markets :-) and sell their products as superior on the security side.
While I am in "evil" mood: The german train system is about to be IPO'ed, and there's a lot of debate going on here about details of the contract. What is most interesting but not being debated:
All real estate owned by the Deutsche Bahn AG (the privatized version of the german train system that is going to be floated) is in the books with it's value upon acquisition -- meaning it's value in 1935. The real estate in possession of the DB is, by today's value, worth several times more than the total money they expect to get out of the IPO.
If I was an investment banker, I'd gang up with a bunch of private equity folks, buy the majority in the DB AG once it is IPO'd, and then sell of the real estate. Other countries (USA, Britain) survive without a decent train system, too, and I wouldn't care as I'd have a Rolls and a driver.
Allright, enough of the devil's advocate mode. It was fun seeing my brother the last weekend,
and we always come up with good ideas ;)
This is a big opportunity for MS to move into all their markets :-) and sell their products as superior on the security side.
While I am in "evil" mood: The german train system is about to be IPO'ed, and there's a lot of debate going on here about details of the contract. What is most interesting but not being debated:
All real estate owned by the Deutsche Bahn AG (the privatized version of the german train system that is going to be floated) is in the books with it's value upon acquisition -- meaning it's value in 1935. The real estate in possession of the DB is, by today's value, worth several times more than the total money they expect to get out of the IPO.
If I was an investment banker, I'd gang up with a bunch of private equity folks, buy the majority in the DB AG once it is IPO'd, and then sell of the real estate. Other countries (USA, Britain) survive without a decent train system, too, and I wouldn't care as I'd have a Rolls and a driver.
Allright, enough of the devil's advocate mode. It was fun seeing my brother the last weekend,
and we always come up with good ideas ;)
Tuesday, May 23, 2006
Saturday, May 20, 2006
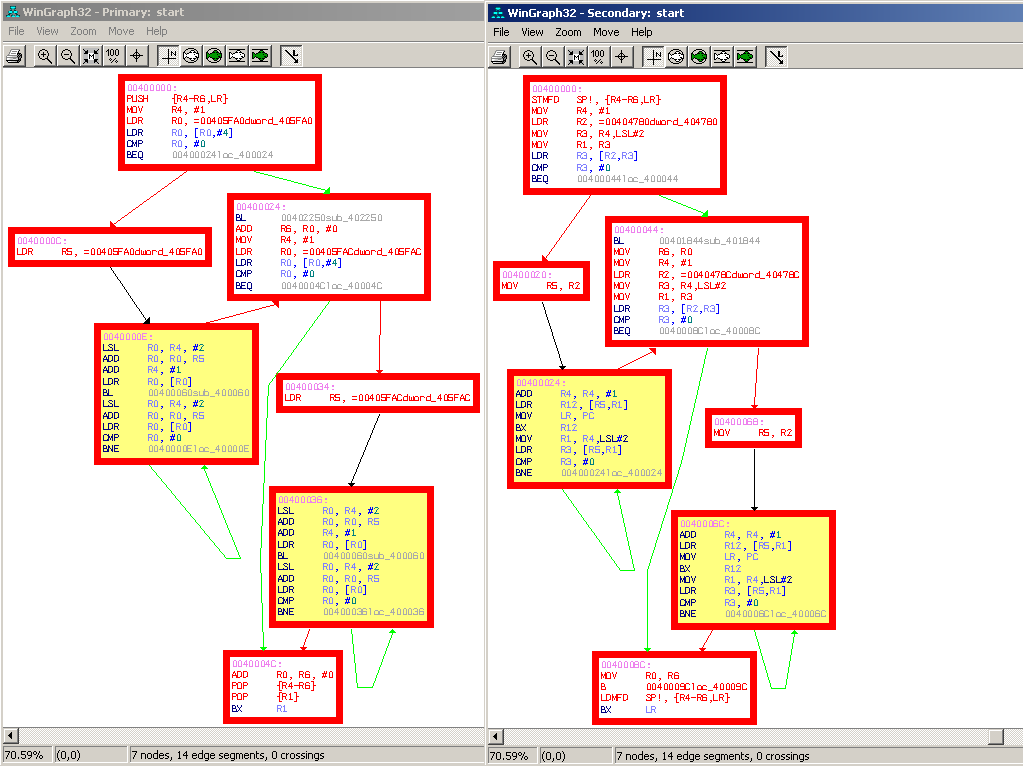 The Vodafone virus dropped by today and brought us some mobile viruses to play with - thanks ! :-)
The Vodafone virus dropped by today and brought us some mobile viruses to play with - thanks ! :-)So cross-platform diffing can be fun -- Rolf ran a diff of Commwarrior.B against Commwarrior.C today, and while B is compiled for standard ARM, C is compiled in 'thumb mode', which is pretty much the same as being compiled for a different CPU (thumb means that all instructions are different).
The amusing result is that even though the compilation is for a different platform, we still get roughly 61% of the functions matched. And the functions, which are clearly the same on the 'structural' (e.g. flowgraph) - level, have completely different instructions, and manual inspection will confirm that these differing instructions end up doing the same.
For those of you that want to verify things manually, click here.
Quote from Lock, Stock and Two Smoking Barrels: "I don't care who you use as long as they are not complete muppets".
Having MSOffice 0day is not terribly hard, but one should not burn it by making it drop standard, off-the-shelf, poorly-written bot software. The stealth advantage that one has by sending .DOC files into an organisation should not be given up by creating empty SYS files or dropping DLLs.
Also, registry key adding for getting control on reboot is kinda suboptimal.
I am kinda curious to know how they got caught, but my guess is that the bad QA on the internet explorer injection raised enough crashes to make people investigate.
On a side note, this highlights a few common problems people face when doing client side attacks:
Having MSOffice 0day is not terribly hard, but one should not burn it by making it drop standard, off-the-shelf, poorly-written bot software. The stealth advantage that one has by sending .DOC files into an organisation should not be given up by creating empty SYS files or dropping DLLs.
Also, registry key adding for getting control on reboot is kinda suboptimal.
I am kinda curious to know how they got caught, but my guess is that the bad QA on the internet explorer injection raised enough crashes to make people investigate.
On a side note, this highlights a few common problems people face when doing client side attacks:
- One-shot-ness -- any exploit you write is a one-shot and should work reliably
- Process recovery -- any exploit you write needs to be able to recover and have the exploited application resume as if nothing happened. This is a tad hard if you've written 200 megs of garbage to the heap.
- Lack of complete pre-attack intel on the target environment -- I don't know what went wrong when they injected into iexplore, but they must've been confident that their code was good enough. This means they tested it on a testbed which didn't reflect the actual target.
- Lack of attack focus -- I am quite convinced that they could've had a simpler, stealthier, and more stable bot component if they had thought more thoroughly about what their goal in this attack was
Friday, May 19, 2006
For those that are into malware classification, here's some code that one
can include in a piece of malware to skew the Levenshtein distance described
in the recently published MS paper.
can include in a piece of malware to skew the Levenshtein distance described
in the recently published MS paper.
int j, i = random_integer_in_range(0, 50000);
FILE *f;
for( j = 0; j < i; j++ ){
f = fopen("c:\\test.txt", "rt");
flose(f);
}
Tuesday, May 16, 2006
Behavioural classification of malware
Today is a good day: I got my math homework done before it has to be handed in, and that leaves me some free time to blog :-)
Dana Epp has a post referring to an entry by Tony Lee referencing an EICAR paper on automated malware classification using behavioural analysis. I am not totally unbiased on this as we at SABRE have been working a lot on structural classification of malware recently, so take my following criticism with a grain of salt.
I personally think the approach in the paper is suboptimal for the following reasons:
I'm not saying the paper isn't good or doesn't touch valid points, but behaviour is so trivially randomized even from a high-level-language level that the approach in the paper is next to pointless once malware authors target it.
On to something kinda different:
A more general question we have to ask ourselves is: Do we really want to measure the accuracy of new, automated malware classification algorithms by comparing them to the results of the manual classification done by AV-vendors so far, which had neither efficient information sharing nor any clear methodology as to how to name malware ? Using any sort of machine learning based on the AV-industry provided datasets needs to be very resilient to partially incorrect input data, as a good number of bots seem to be more or less arbitrarily named.
Anyhow, time to go to sleep and read Courtois eprint paper
Today is a good day: I got my math homework done before it has to be handed in, and that leaves me some free time to blog :-)
Dana Epp has a post referring to an entry by Tony Lee referencing an EICAR paper on automated malware classification using behavioural analysis. I am not totally unbiased on this as we at SABRE have been working a lot on structural classification of malware recently, so take my following criticism with a grain of salt.
I personally think the approach in the paper is suboptimal for the following reasons:
- By using behavioural data, we can only classify an executable based on things it does in the observed timeframe. Any time-delayed trigger (that e.g. triggers two months from now) is hard to see, and the application might just sleep until then. How do we classify something that just came into our networks ? We can't classify it until it starts becoming "active".
- It is trivial even for somebody who knows only rudimentary programming to modify a program so that the modifed program only has a few (~4 ?) lines of code more than the original program, yet it's Levenshtein distance as measure in the paper is arbitrarily large. As it stands, adding file writes in a loop should be enough, and the Levenshtein distance can be arbitrarily increased by more loop iterations.
- The paper cites on-access deobfuscation as a principal problem that static analysis cannot easily deal with -- but from (2) it follows that on-access deobfuscation can be coupled with Levenstein-distance-maximizing code in a trivial manner, breaking the approach that was proposed as superior in the paper. The claim that runtime analysis can effectively bypass the need to deal with obfuscation is simply not true if the application ever targets the event collection by 'junking' it with bogus events.
I'm not saying the paper isn't good or doesn't touch valid points, but behaviour is so trivially randomized even from a high-level-language level that the approach in the paper is next to pointless once malware authors target it.
On to something kinda different:
A more general question we have to ask ourselves is: Do we really want to measure the accuracy of new, automated malware classification algorithms by comparing them to the results of the manual classification done by AV-vendors so far, which had neither efficient information sharing nor any clear methodology as to how to name malware ? Using any sort of machine learning based on the AV-industry provided datasets needs to be very resilient to partially incorrect input data, as a good number of bots seem to be more or less arbitrarily named.
Anyhow, time to go to sleep and read Courtois eprint paper
Friday, May 12, 2006
Microsofts built-in firewall has some really annoying things to it. I am running a laptop connected to an untrusted network and an instance of VMWare connected on a different interface. If I disable the firewall on the VMWare interface, it automatically gets disabled on the global interface. Very cute. Can we get this fixed ?
Monday, May 08, 2006
Saturday, April 29, 2006
More on automated malware classification and naming
So after having posted some graphs without further explanation yesterday, I think it is a good idea to actually explain what these graphs were all about.
We at SABRE have worked on automated classification of malware over the last few weeks. Essentially, thanks to Rolf's relentless optimization efforts and a few algorithmic tricks, the BinDiff2 engine is blazingly fast. As an example, we can diff a 30000+ functions router image in under 8 minutes on my laptop now, and this includes reading the data from the IDA database. That means that we can afford to run a couple of hundred thousand diffs on a collection of malware samples, and to then work with the results -- malware is rarely of a size exceeding 1000 functions, and anything of that size is diffed in a few seconds.
So we were provided with a few thousand samples of bots that Thorsten Holz had collected. The samples themselves were only marked with their MD5sum.
We ran the first few hundred through a very cheap unpacking tool and then disassembled the results. We than diffed each sample against each other. Afterwards, we ran a phylogenetic clustering algorithm on top of the results, and ended up with this graph:
 The connected components have been colored, and a hi-res variant of this image can be looked at here.
The connected components have been colored, and a hi-res variant of this image can be looked at here.
The labels on the edges are measures of graph-theoretic similarity -- a value of 1.000 means that the executables are identical, lower values give percentage-wise similarity. We have decided in this graph to keep everything with a similarity of 50% or greater in one family, and cut off everything else.
So what can we read from this graph ? First of all, it is quite obvious that although we have ~200 samples, we only have two large families, three small families, two pairs of siblings and a few isolated samples. Secondly, even the most "distant relatives" in the cyan-colored cluster are 75% similar, the most "distant relatives" in the green cluster on the right are still 58% similar. If we cut the green cluster on the right into two subclusters, the most distant relatives are 90% similar.
Now, in order to double-check our results with what AV folks already know, Thorsten Holz provided us with the results of a run of ClamAV on the samples, and we re-generated the graphs with the names of those samples that were recognized by ClamAV.
The result looks like this:
 (check this graphic for a hi-res version which you will need to make sense of the following ;)
(check this graphic for a hi-res version which you will need to make sense of the following ;)
What can we learn from this graph ? First of all, we see that the various members of the GoBot family are so similar to the GhostBot branch that we should probably consider GoBot and GhostBot to be of the same family. The same holds for the IrcBot and GoBot-3 samples and for the Gobot.R and Downloader.Delf-35 samples -- why do we have such heavily differing names when the software in question is so similar ?
We seem to consider Sasser.B and Sasser.D to be of the same family with a similarity of 69%, but Gobot.R and Downloader.Delf-35, which are a lot more similar, have their own families ?
What we can also see is that we have two samples in the green cluster (GoBot, IRCBot, GhostBot, Downloader.Delf) that have not been recognized by ClamAV and that seem to have their own branch in the family tree:

Apparently, these two specimen are new veriants of the above family tree.
Miscallenous other things we can learn from this (admittedly small) graph:
So much fun.
Anyhow, if you guys find this stuff interesting, drop me mail about this at halvar.flake@sabre-security.com ...
So after having posted some graphs without further explanation yesterday, I think it is a good idea to actually explain what these graphs were all about.
We at SABRE have worked on automated classification of malware over the last few weeks. Essentially, thanks to Rolf's relentless optimization efforts and a few algorithmic tricks, the BinDiff2 engine is blazingly fast. As an example, we can diff a 30000+ functions router image in under 8 minutes on my laptop now, and this includes reading the data from the IDA database. That means that we can afford to run a couple of hundred thousand diffs on a collection of malware samples, and to then work with the results -- malware is rarely of a size exceeding 1000 functions, and anything of that size is diffed in a few seconds.
So we were provided with a few thousand samples of bots that Thorsten Holz had collected. The samples themselves were only marked with their MD5sum.
We ran the first few hundred through a very cheap unpacking tool and then disassembled the results. We than diffed each sample against each other. Afterwards, we ran a phylogenetic clustering algorithm on top of the results, and ended up with this graph:
 The connected components have been colored, and a hi-res variant of this image can be looked at here.
The connected components have been colored, and a hi-res variant of this image can be looked at here.{kind=link}
The labels on the edges are measures of graph-theoretic similarity -- a value of 1.000 means that the executables are identical, lower values give percentage-wise similarity. We have decided in this graph to keep everything with a similarity of 50% or greater in one family, and cut off everything else.
So what can we read from this graph ? First of all, it is quite obvious that although we have ~200 samples, we only have two large families, three small families, two pairs of siblings and a few isolated samples. Secondly, even the most "distant relatives" in the cyan-colored cluster are 75% similar, the most "distant relatives" in the green cluster on the right are still 58% similar. If we cut the green cluster on the right into two subclusters, the most distant relatives are 90% similar.
Now, in order to double-check our results with what AV folks already know, Thorsten Holz provided us with the results of a run of ClamAV on the samples, and we re-generated the graphs with the names of those samples that were recognized by ClamAV.
The result looks like this:
 (check this graphic for a hi-res version which you will need to make sense of the following ;)
(check this graphic for a hi-res version which you will need to make sense of the following ;){kind=link}
What can we learn from this graph ? First of all, we see that the various members of the GoBot family are so similar to the GhostBot branch that we should probably consider GoBot and GhostBot to be of the same family. The same holds for the IrcBot and GoBot-3 samples and for the Gobot.R and Downloader.Delf-35 samples -- why do we have such heavily differing names when the software in question is so similar ?
We seem to consider Sasser.B and Sasser.D to be of the same family with a similarity of 69%, but Gobot.R and Downloader.Delf-35, which are a lot more similar, have their own families ?
What we can also see is that we have two samples in the green cluster (GoBot, IRCBot, GhostBot, Downloader.Delf) that have not been recognized by ClamAV and that seem to have their own branch in the family tree:
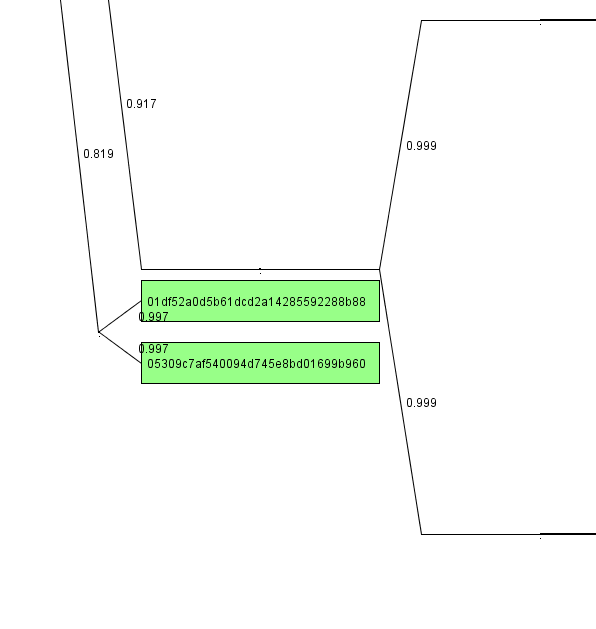
Apparently, these two specimen are new veriants of the above family tree.
Miscallenous other things we can learn from this (admittedly small) graph:
- We have 6 variants of Trojan.Crypt.B here that go undetected by ClamAV
- We have an undetected variant of Worm.Korgo.Z
- PadoBot and Korgo.H are very closely related, whereas Korgo.Z does not appear to be very similar. Generally, the PadoBot and the Korgo.H/Korgo.Y/Korgo.AJ family seem to be just one family.
So much fun.
Anyhow, if you guys find this stuff interesting, drop me mail about this at halvar.flake@sabre-security.com ...
Friday, April 28, 2006
Also, Rolf has created a shockwave where he shows how to use BinDiff to find GPL violations.
Check it here...
Check it here...
Automated classification of malware is easier than it seems once you have the right infrastructure -- in our case consisting of the BinDiff2 engine, a few generic unpacking tools and a graph layout program.
I have uploaded some graphics:
This is just a collection of arbitrary malware whose members were identified by use of AV programs. We then BinDiff'ed all samples and used some phylogenetics algorithm to draw this diagram. The results are quite neat, although we did not filter library functions, so some very simple viruses have high similarity due to the fact that 95% of their code is statically linked library code.
This is a collection of a few hundred bots. They were collected on Thorsten Holz's Honeynet, and we auto-unpacked them and then did the BinDiffing/tree generation. This time, we did filter libraries as good as we could. The 184 samples here all have different MD5sums, but the
largest majority belongs to essentially two families. All in all, we have ~5 "families", two pairs
of "siblings" and 9 isolated species here. Fun.
I have uploaded some graphics:
This is just a collection of arbitrary malware whose members were identified by use of AV programs. We then BinDiff'ed all samples and used some phylogenetics algorithm to draw this diagram. The results are quite neat, although we did not filter library functions, so some very simple viruses have high similarity due to the fact that 95% of their code is statically linked library code.
{kind=link}
This is a collection of a few hundred bots. They were collected on Thorsten Holz's Honeynet, and we auto-unpacked them and then did the BinDiffing/tree generation. This time, we did filter libraries as good as we could. The 184 samples here all have different MD5sums, but the
{kind=link}
largest majority belongs to essentially two families. All in all, we have ~5 "families", two pairs
of "siblings" and 9 isolated species here. Fun.
Wednesday, April 26, 2006
I am in a state of brainfry. Which I guess is good. Exhaustion can be fun. I think I haven't worked as hard as I am working at the moment in quite a while, and while the results move slowly (due to fighting on many fronts), they move, and in a good direction. Now I will sleep. Ah, for those into this sorta stuff, here is what claims to be a significant improvement of the FMS attack on RC4. Good read, although nothing worldmoving, and I haven't verified the results fully yet.
Wednesday, April 19, 2006
Language in thought and action or "what's correct vs. what's right"
Everybody should IMO, at some point of his life, have read Hayakawa's "Language in thought and action". It is a book about semantics, of words and their meanings. Semantics pop up in very amusing situations, for example in code analysis/review, and a few other places.
A small thing to take out of that book is that the entry in a dictionary is not the definitive meaning of a word, but that the meaning of the word is (somewhat circularly) defined as what the collective mind thinks this word means.
There's currently an bugtraq about the way that GCC treats certain 'invalid language' constructs. While I find very few things more amusing than compiler changes breaking formerly working code, I also find the reaction of everybody except fefe on that list to be very amusing: Instead of relying on what everybody thinks the meaning of that line of code is, they refer to the written standard. In essence, they look up the meaning of a word in a dictionary.
Yes, standards are important. But there is a difference between the standard on paper and the 'standard', meaning the way everybody perceives (and writes in) that language. And due to the fact that C's standard has been in some ways unenforced for 20+ years there are lots of existing 'standard' idioms (such as Fefe's int wrap check) that are not valid by the written standard.
What we're trying to do here is the equivalent of not correcting a child's grammar for 20 years, allowing it to play with other kids with broken grammar and always understanding what the child wanted to say when it used broken grammar. And then, once it turned 20, we cross out the constructs with bad grammar from everything he says and interpret the rest.
If the construct is so invalid, have the compiler warn at least :)
This sounds like a sure recipe for disaster to me :)
I had a discussion with Rolf yesterday about GCC's ghastlyness, and the fact that we're spending a good bit of our time fighting compiler woes instead of coding. Then again, we're doing something rather odd: We're trying to write C++ code with GCC, which frankly, doesn't work. I am very inclined to switch to Intel's CPP.
Oh, while I am at ranting: On which CPU is GCC's weird optimization of passing arguments by subtracting from ESP and then issuing several 'mov [esp+const], reg' faster than push/call ? Sure, on a cycle-by-cycle basis each instruction is faster, but has anyone ever considered the impact of a 3*size increase in the code on CPU caching ?
I'll shut up now before this deteriorates into more ranting.
Everybody should IMO, at some point of his life, have read Hayakawa's "Language in thought and action". It is a book about semantics, of words and their meanings. Semantics pop up in very amusing situations, for example in code analysis/review, and a few other places.
A small thing to take out of that book is that the entry in a dictionary is not the definitive meaning of a word, but that the meaning of the word is (somewhat circularly) defined as what the collective mind thinks this word means.
There's currently an bugtraq about the way that GCC treats certain 'invalid language' constructs. While I find very few things more amusing than compiler changes breaking formerly working code, I also find the reaction of everybody except fefe on that list to be very amusing: Instead of relying on what everybody thinks the meaning of that line of code is, they refer to the written standard. In essence, they look up the meaning of a word in a dictionary.
Yes, standards are important. But there is a difference between the standard on paper and the 'standard', meaning the way everybody perceives (and writes in) that language. And due to the fact that C's standard has been in some ways unenforced for 20+ years there are lots of existing 'standard' idioms (such as Fefe's int wrap check) that are not valid by the written standard.
What we're trying to do here is the equivalent of not correcting a child's grammar for 20 years, allowing it to play with other kids with broken grammar and always understanding what the child wanted to say when it used broken grammar. And then, once it turned 20, we cross out the constructs with bad grammar from everything he says and interpret the rest.
If the construct is so invalid, have the compiler warn at least :)
This sounds like a sure recipe for disaster to me :)
I had a discussion with Rolf yesterday about GCC's ghastlyness, and the fact that we're spending a good bit of our time fighting compiler woes instead of coding. Then again, we're doing something rather odd: We're trying to write C++ code with GCC, which frankly, doesn't work. I am very inclined to switch to Intel's CPP.
Oh, while I am at ranting: On which CPU is GCC's weird optimization of passing arguments by subtracting from ESP and then issuing several 'mov [esp+const], reg' faster than push/call ? Sure, on a cycle-by-cycle basis each instruction is faster, but has anyone ever considered the impact of a 3*size increase in the code on CPU caching ?
I'll shut up now before this deteriorates into more ranting.
Monday, April 17, 2006
http://teh-win.blogspot.com/ has (as usual) an amusing read up, which at one step harps on a point that I can't support enough: 0days != hacking. Almost all "real" hacking is done via transitive trust (thus the same goes for pentests). 0days allow you to more quickly get _some_ trust to exploit transitively, but the "real" work is done on transitive trust. And transitive trust and "real" hacking gets too little credit at security conferences, mainly because any "real" research here is by direct implication illegal ("... I wrote this worm that exploits transitive trust ... and I have some empirical data on it's spreading capabilities *cough* ...").
Now I just need to find a dictionary that explains me what "branler la nouille en mode noyau" means ;)
Now I just need to find a dictionary that explains me what "branler la nouille en mode noyau" means ;)
Publication Economics and Cryptography Research
Something I cannot cease to wonder is why historically there has been so little published research on the cryptanalysis of block ciphers. There seem to be millions of articles describing "turning some math guy's favourite mathematical problem into an asymetric crypto algorithm" and a similar flood of "fair coin flipping if all participants are drunk cats and the coin is a ball of yarn"-sort of papers. All in all, there have been perhabs less than 20 REALLY important papers in the analysis of symetric crypto in ... uhm ... the last 10 years (I count hashes as symetric crypto here).
What's the reason for this ?
First of all, symetric crypto tends to not have a "nice" mathematical structure. This changed somewhat with AES, but almost everything on the symetric side is rather ugly to look at. Sure, everything can be written as large multivariate polynomials over GF(2), but that's just a prettier way of writing a large boolean formulae. So it's hard for anybody in a math department to justify working on something that is "like a ring, but not quite, or like a group, but not quite".
Secondly, starting to build a protocol or proposing a new asymetric cipher is something that a sane researcher (that has not earned tenure yet) can do in a "short" window of time. Setting out to break a significant crypto algorithm could very easily lead to "10+ years in the wilderness and a botched academic career due to a lack of publications". The result: If you haven't earned tenure yet, and want to work in crypto, you work on the constructive side.
I find this to be a bit frustrating. I'd like to work on ciphers, specifically on BREAKING ciphers. I seriously could never get myself excited about defense. I wouldn't mind spending a few years of my life on one cipher. But academically, and career wise, this is clear suicide.
Perhabs we should value "destructive" research more. From my personal viewpoint, a break in a significant cipher is worth more than 20 papers on fair coin flipping in the absence of gravity. But when it comes to giving out tenure, it almost seems that the 20 papers outweigh the one.
Ahwell. Enough ranting, back to work.
Something I cannot cease to wonder is why historically there has been so little published research on the cryptanalysis of block ciphers. There seem to be millions of articles describing "turning some math guy's favourite mathematical problem into an asymetric crypto algorithm" and a similar flood of "fair coin flipping if all participants are drunk cats and the coin is a ball of yarn"-sort of papers. All in all, there have been perhabs less than 20 REALLY important papers in the analysis of symetric crypto in ... uhm ... the last 10 years (I count hashes as symetric crypto here).
What's the reason for this ?
First of all, symetric crypto tends to not have a "nice" mathematical structure. This changed somewhat with AES, but almost everything on the symetric side is rather ugly to look at. Sure, everything can be written as large multivariate polynomials over GF(2), but that's just a prettier way of writing a large boolean formulae. So it's hard for anybody in a math department to justify working on something that is "like a ring, but not quite, or like a group, but not quite".
Secondly, starting to build a protocol or proposing a new asymetric cipher is something that a sane researcher (that has not earned tenure yet) can do in a "short" window of time. Setting out to break a significant crypto algorithm could very easily lead to "10+ years in the wilderness and a botched academic career due to a lack of publications". The result: If you haven't earned tenure yet, and want to work in crypto, you work on the constructive side.
I find this to be a bit frustrating. I'd like to work on ciphers, specifically on BREAKING ciphers. I seriously could never get myself excited about defense. I wouldn't mind spending a few years of my life on one cipher. But academically, and career wise, this is clear suicide.
Perhabs we should value "destructive" research more. From my personal viewpoint, a break in a significant cipher is worth more than 20 papers on fair coin flipping in the absence of gravity. But when it comes to giving out tenure, it almost seems that the 20 papers outweigh the one.
Ahwell. Enough ranting, back to work.
Friday, March 31, 2006
Wednesday, March 15, 2006
My latest travel madness is over, and after 4 weeks on the road I am home again. The last week of that travelling I spent mostly sick -- that means I went to BlueHat for all the work and then had to skip all the fun. Furthermore, I learnt a bunch of interesting things concerning sinusitis and pressure changes during intercontinental flights.
Those that know me know I am a graph nerd (and by extension an OBDD nerd), so check
this paper for some more OBDD fun.
While you are doing your brain some good, you might as well read this paper -- it is fascinating and very useful at the same time.
Now, I am just enjoying the second day of my first "weekend" in a month -- I decided not to work for two days, and spent the first 34 hours of these two days in bed. Now I am cleaning my flat and will be reading some fun shit lateron (compact riemann surfaces perhabs?). Or I will call Ero and see if he is up for a round of Go.
I saw that Ilfak reads my BH presentations -- I am flattered and thus will need to try harder with them the next time.
One of the highlights of BlueHat was meeting a bunch of MS folks that I respect A LOT: Jon, Brandon, Alex, Pete, Jan -- thanks for being awesome.
I read many good things about OCaml recently, and a bunch of very interesting programs (ASTREE and SLAM/SDV) seem to be written in it. Can someone offer some comments on it ?
Those that know me know I am a graph nerd (and by extension an OBDD nerd), so check
this paper for some more OBDD fun.
While you are doing your brain some good, you might as well read this paper -- it is fascinating and very useful at the same time.
Now, I am just enjoying the second day of my first "weekend" in a month -- I decided not to work for two days, and spent the first 34 hours of these two days in bed. Now I am cleaning my flat and will be reading some fun shit lateron (compact riemann surfaces perhabs?). Or I will call Ero and see if he is up for a round of Go.
I saw that Ilfak reads my BH presentations -- I am flattered and thus will need to try harder with them the next time.
One of the highlights of BlueHat was meeting a bunch of MS folks that I respect A LOT: Jon, Brandon, Alex, Pete, Jan -- thanks for being awesome.
I read many good things about OCaml recently, and a bunch of very interesting programs (ASTREE and SLAM/SDV) seem to be written in it. Can someone offer some comments on it ?
Sunday, February 26, 2006
My travel schedule remains insane, and I notice that thinking about 'hard' problems is very difficult while travelling. Sigh. Anyhow, those that had beer with me in the last year and a half or so know that I have a severe interest in OBDD-like structures and their applications to cryptanalysis.
So I just wanted to put a reference here to
http://eprint.iacr.org/2006/072.pdf
So I just wanted to put a reference here to
http://eprint.iacr.org/2006/072.pdf
Saturday, February 18, 2006
We at SABRE will be giving a 3-day advanced reverse engineering course this fall in Frankfurt. Check this link if you are interested in that sorta stuff.
Tuesday, February 07, 2006
History is important. It is VERY cool to see DaveG posting old 8LGM memorabilia. Thanks !
I have to hit the train now. Will read this
on the train -- skimmed it in the subway, and it looks ridiculously interesting (if you happen to be into solving systems of multivariate polynomial equations or into classical algebraic geometry in general). It claims to contain a bridge between multivariate polys over finite fields and univariate polynomials over certain extensions of the same field. We'll see how good it actually is.
I have to hit the train now. Will read this
on the train -- skimmed it in the subway, and it looks ridiculously interesting (if you happen to be into solving systems of multivariate polynomial equations or into classical algebraic geometry in general). It claims to contain a bridge between multivariate polys over finite fields and univariate polynomials over certain extensions of the same field. We'll see how good it actually is.
Hans Dobbertin died of cancer on the 2nd of February. I did not know him well - I had switched universities in order to write my thesis under his supervision, but shortly after I had arrived at the new university he fell ill. The few times that we talked it was a lot of fun though, and I respected him greatly. There are only a limited number of professors I met in my life that really understood and seemed to appreciate what I am doing, and it did not take much to explain it to Prof Dobbertin (which might have to do with his work prior to becoming a university professor). My condolescences to his family and those that were close to him.
Aside from the personal sadness I feel it is a setback for my Diplomarbeit. But well, that is nothing in the big picture really.
Aside from the personal sadness I feel it is a setback for my Diplomarbeit. But well, that is nothing in the big picture really.
Sunday, January 15, 2006
My schedule in the next weeks sucks. Wednesday I am flying to London. The following Saturday to DC. Coming back the next Sunday. Possibly need to go to Paris the day after. Need to fly to Dresden on Tuesday night, and come back on Thursday morning (in time for lectures). I hope studies don't suffer too much.
It's damn cool to have Rolf & Ero here. Shit is moving fast. We're getting lots done. :-)
It's damn cool to have Rolf & Ero here. Shit is moving fast. We're getting lots done. :-)
Subscribe to:
Comments (Atom)