So after having posted some graphs without further explanation yesterday, I think it is a good idea to actually explain what these graphs were all about.
We at SABRE have worked on automated classification of malware over the last few weeks. Essentially, thanks to Rolf's relentless optimization efforts and a few algorithmic tricks, the BinDiff2 engine is blazingly fast. As an example, we can diff a 30000+ functions router image in under 8 minutes on my laptop now, and this includes reading the data from the IDA database. That means that we can afford to run a couple of hundred thousand diffs on a collection of malware samples, and to then work with the results -- malware is rarely of a size exceeding 1000 functions, and anything of that size is diffed in a few seconds.
So we were provided with a few thousand samples of bots that Thorsten Holz had collected. The samples themselves were only marked with their MD5sum.
We ran the first few hundred through a very cheap unpacking tool and then disassembled the results. We than diffed each sample against each other. Afterwards, we ran a phylogenetic clustering algorithm on top of the results, and ended up with this graph:
 The connected components have been colored, and a hi-res variant of this image can be looked at here.
The connected components have been colored, and a hi-res variant of this image can be looked at here.{kind=link}
The labels on the edges are measures of graph-theoretic similarity -- a value of 1.000 means that the executables are identical, lower values give percentage-wise similarity. We have decided in this graph to keep everything with a similarity of 50% or greater in one family, and cut off everything else.
So what can we read from this graph ? First of all, it is quite obvious that although we have ~200 samples, we only have two large families, three small families, two pairs of siblings and a few isolated samples. Secondly, even the most "distant relatives" in the cyan-colored cluster are 75% similar, the most "distant relatives" in the green cluster on the right are still 58% similar. If we cut the green cluster on the right into two subclusters, the most distant relatives are 90% similar.
Now, in order to double-check our results with what AV folks already know, Thorsten Holz provided us with the results of a run of ClamAV on the samples, and we re-generated the graphs with the names of those samples that were recognized by ClamAV.
The result looks like this:
 (check this graphic for a hi-res version which you will need to make sense of the following ;)
(check this graphic for a hi-res version which you will need to make sense of the following ;){kind=link}
What can we learn from this graph ? First of all, we see that the various members of the GoBot family are so similar to the GhostBot branch that we should probably consider GoBot and GhostBot to be of the same family. The same holds for the IrcBot and GoBot-3 samples and for the Gobot.R and Downloader.Delf-35 samples -- why do we have such heavily differing names when the software in question is so similar ?
We seem to consider Sasser.B and Sasser.D to be of the same family with a similarity of 69%, but Gobot.R and Downloader.Delf-35, which are a lot more similar, have their own families ?
What we can also see is that we have two samples in the green cluster (GoBot, IRCBot, GhostBot, Downloader.Delf) that have not been recognized by ClamAV and that seem to have their own branch in the family tree:
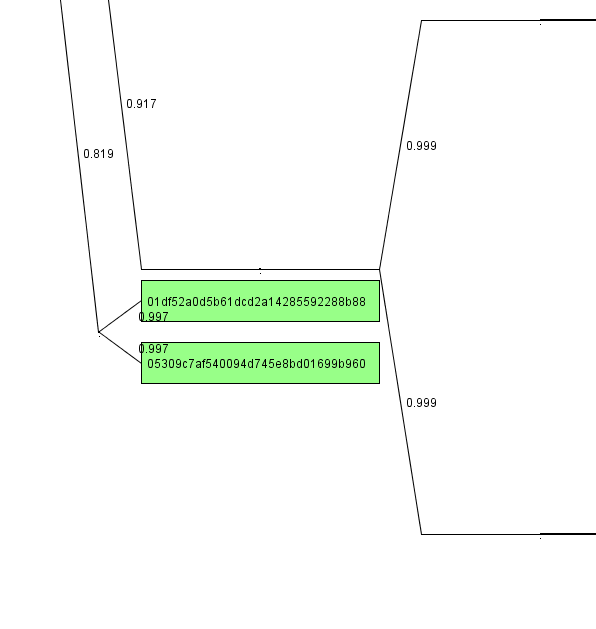
Apparently, these two specimen are new veriants of the above family tree.
Miscallenous other things we can learn from this (admittedly small) graph:
- We have 6 variants of Trojan.Crypt.B here that go undetected by ClamAV
- We have an undetected variant of Worm.Korgo.Z
- PadoBot and Korgo.H are very closely related, whereas Korgo.Z does not appear to be very similar. Generally, the PadoBot and the Korgo.H/Korgo.Y/Korgo.AJ family seem to be just one family.
So much fun.
Anyhow, if you guys find this stuff interesting, drop me mail about this at halvar.flake@sabre-security.com ...
3 comments:
Very interesting analysis. Have you thought about incorporating release/discovery date information for each sample into the model? That might allow you to see how different families of malware evolved (temporal relationships) in addition to how closely they are related.
Here is my take on "... IrcBot and GoBot-3 ... and ... Gobot.R and Downloader.Delf-35 ... why do we have such ... differing names ...".
I think it's because of generic names. Symantec detects some GoBot variants as W32.Gobot.A and other variants simply as
Backdoor.IRC.Bot (which is a generic name for a "yet to be analyzed IRC bot"). Downloader.Delf is common name for downloader trojans written in Delphi. Possibly some of these were automatically processed by an AV vendor and a generic name was chosen. Or the analyst had little time to determine family and went with a "safe" common name and ClamAV just copied that vendor's name.
Also, curious: which very cheap unpacking tool did you use? Feel free to email me.
Nick
Shocking as it might be, I think F-Secure does not use any sort of automation in order to classify malware. (Same goes for probably most other AVs).
I'm now working together with Halvar and Rolf in Sabre Security so I feel I can comment of how this similarity measure compares with the one I developed in the 2004 VB paper ;) . There are some differences; mainly the usage of BinDiff in order to collect the similarity information (which is light-years ahead of my the mini-differ I had developed then) and some polished clustering algorithms. All together leads to much better results than the ones obtained in the paper.
Post a Comment