So it seems the APEG paper is getting a lot of attention these days, and some of the conclusions that are (IMO falsely) drawn from it are:
- patch time to exploit is approaching zero
- patches should be obfuscated
- BinDiff-style algorithms are used to find changes between the patched and unpatched version
- The vulnerable locations are identified.
- Constraint formulas are generated from the code via three different methods:
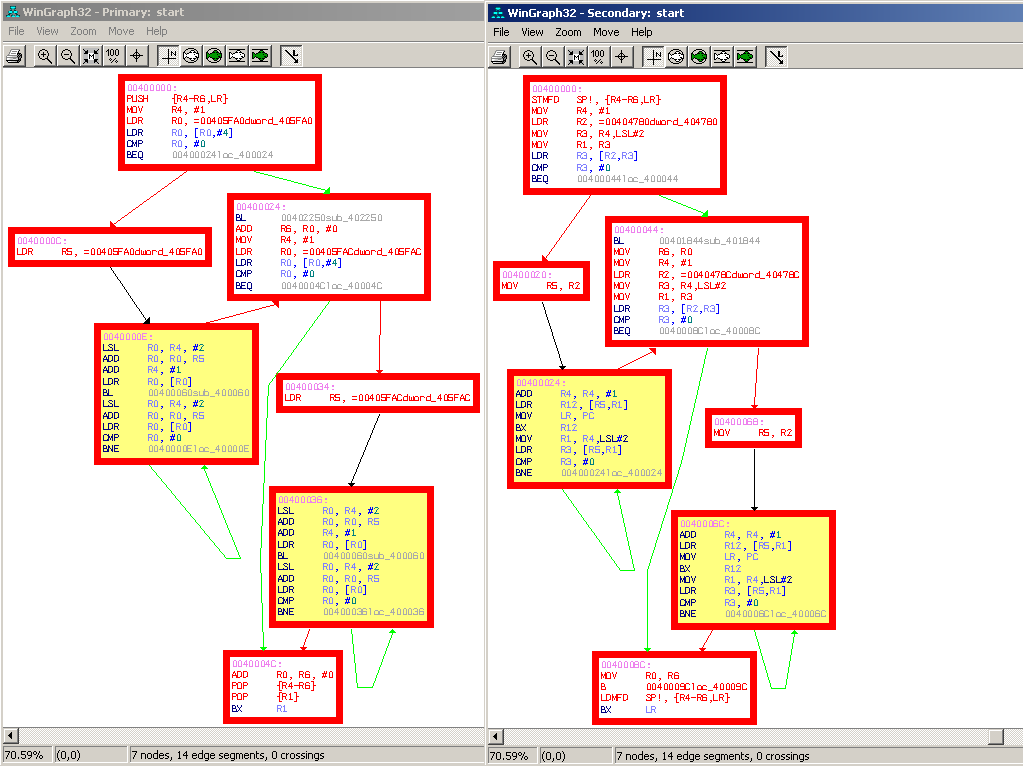
- Static: A graph of all basic blocks on code paths between the vulnerability and the data input into the application is generated, and a constraint formula is generated from this graph.
- Dynamic: An execution trace is taken, and if the vulnerability occurs on a program path that one can already execute. Constraints are generated from this path.
- Dynamic/Static: Instead of going from data input to target vulnerability (as in the static approach), one can use an existing path that comes "close" to the vulnerability as starting point from which to proceed with the static approach.
- The (very powerful) solver STP is used for solving these constraint systems, generating inputs that exercise a particular code path that triggers the vulnerability.
- A number of vulnerabilities are discussed which were successfully triggered using the methods described in the paper
- The conclusion is drawn that within minutes of receiving a patch, attackers can use automatically generated exploits to compromise systems.
What the APEG paper describes is impressive -- using STP is definitely a step forwards, as it appears that STP is a much superior solver to pretty much everything else that's publically available.
It is equally important to keep the limitations of this approach in mind - people are reacting in a panicked manner without necessarily understanding what this can and cannot do.
- Possible NP-hardness of the problem. Solving for a particular path is essentially an instance of SAT, and we know that this can be NP-hard. It doesn't have to be, but the paper indicates many formulas STP cannot solve in reasonable time. While this doesn't imply that these formulas are in fact hard to solve, it shows how much this depends on the quality of your solver and the complexity of the formulas that are generated.
- The method described in the paper does not generate exploits. It triggers vulnerabilities. Anyone who has worked on even a moderately complex issue in the past knows that there is often a long and painful path between triggering an overflow and making use of it. The paper implies that the results of APEG are immediately available to compromise systems. This is, plainly, not correct. If APEG is successful, the results can be used to cause a crash of a process, and I refuse to call this a "compromise". Shooting a foreign politician is not equal to having your intelligence agency compromise him.
- Semantic issues. All vulnerabilities for which this method worked were extremely simple. The actual interesting IGMP overflow Alex Wheeler had discovered, for example, would not be easily dealt with by these methods -- because program state has to be modified for that exploit in a non-trivial way. In essence, a patch can tell you that "this value YY must not exceed XX", but if YY is not direct user data but indirectly calculated through other program events, it is not (yet) possible to automatically set YY.
- The program path between the vulnerability and code that one already knows how to execute is comparatively simple
- The generated equation systems are not too complex for the solver
- The bug is "linear" in the sense that no complicated manipulation of program state is required to trigger the vulnerability
What the paper gets wrong IMO are the conclusions about what should be done in the patching process. It argues that because "exploits can be generated automatically, the patching process needs fixing". This is a flawed argument, as ... uhm ... useful exploits can't (yet) be generated automatically. Triggering a vulnerability is not the same as exploiting it, especially under modern operating systems (due to ASLR/DEP/Pax/GrSec).
The paper proposes a number of ways of fixing the problems with the current patching process:
1. Patch obfuscation. The proposal that zombie-like comes back every few years: Let's obfuscate security patches, and all will be good. The problems with this are multifold, and quite scary:
- Obfuscated executables make debugging for MS ... uhm ... horrible, unless they can undo it themselves
- Obfuscated patches remove an essential liberty for the user: The liberty to have a look at a patch and make sure that the patch isn't in fact a malicious backdoor.
- We don't have good obfuscation methods that do not carry a horrible performance impact.
- Obfuscation methods have the property that they need to be modified whenever attackers break them automatically. The trouble is: Nobody would know if the attackers have broken them. It is thus safe to assume that after a while, the obfuscation would be broken, but nobody would be aware of it.
- Summary: Obfuscation would probably a) impact the user by making his code slower and b) impact the user by disallowing him from verifying that a patch is not malicious and c) create support nightmares for MS because they will have to debug obfuscated code. At the same time, it will not provide long-term security.
3. Faster patch distribution. A laudable goal, nothing wrong with this.
Anyhow, long post, short summary: The APEG paper is really good, but it uses confusing terminology (exploit ~= vulnerability trigger) which leads to it's impact on patch distribution being significantly overstated. It's good work, but the sky isn't falling, and we are far away from generating reliable exploits automatically from arbitrary patches. APEG does generate usable vulnerability triggers for vulnerabilities of a certain form. And STP-style solvers are important.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}